SQLite源码分析6 分页和缓存#
原理#
磁盘之上是page层。
数据库文件以页为单位被分割。每页都有编号。
频繁操作页比如频繁去读某些页,就会造成频繁操作磁盘,如果把数据放入内存,速度会以数量级提高。
但是很多情况不可能把整个数据库文件都放入内存。
那么需要做个有限大小的缓存。每次读页,先去查缓存,如果缓存里没有,才去读磁盘。这样减少了频繁的磁盘io。每个页对应有一个页缓存(page cahce)。
cache状态可为clean,表示缓存中的数据与磁盘一致。即干净的,不需要处理。 状态可为dirty,即缓存数据被改过,是脏的,需要同步到磁盘。page层之上是b树。b树都是用pager的接口,不直接操作磁盘。
这次分析分页和缓存相关流程。
定义#
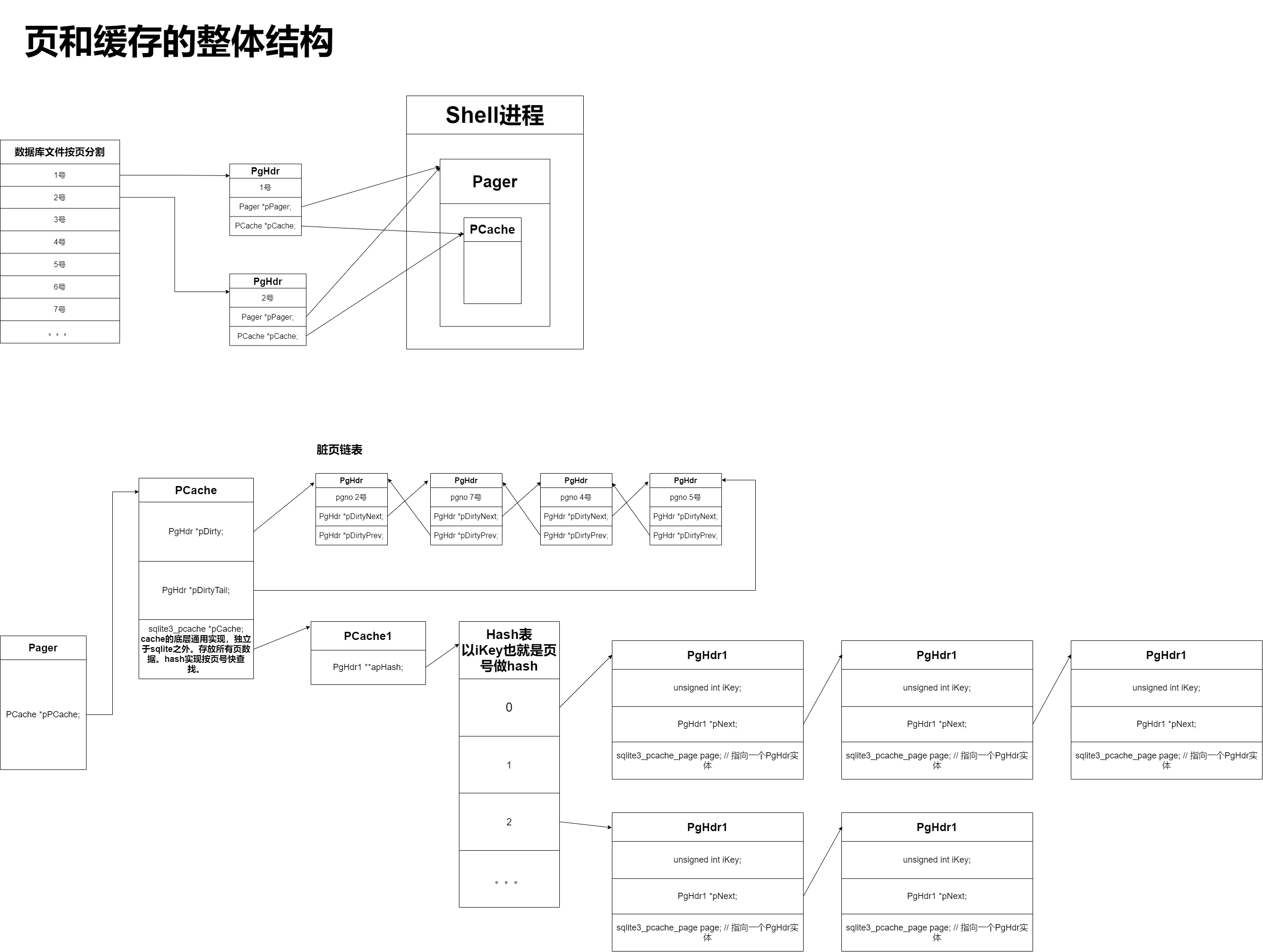
页结构体。包含单个页的信息。每个页对应一个实体。可以有大量实体。
struct PgHdr {
...
void *pData; // 页数据
void *pExtra; // 其他数据
PCache *pCache; // 该页的所属的缓存总管
PgHdr *pDirty; // 脏页链表
Pager *pPager; // 所属的分页器
Pgno pgno; // 页号
PgHdr *pDirtyNext; // 下一个脏页
PgHdr *pDirtyPrev; // 前一个脏页
u16 flags; // 各种标志位。PGHDR_CLEAN、PGHDR_DIRTY、PGHDR_NEED_SYNC等等。
}
cache总管。只有一个实体。在sqlite3PagerOpen中生成。
struct PCache {
...
PgHdr *pDirty, *pDirtyTail; // 脏页列表。pDirty指向头,pDirtyTail指向尾。
int szPage; // 页大小
int nRefSum; // 引用计数
sqlite3_pcache *pCache; // 这里又做了一层,实现底层的cache逻辑,比如按页号搜索的算法、分配cache等。代码在pcache1.c。
}
Pager相当于一个分页总管。存各种配置和分页的总体信息。只有一个实体,在sqlite3PagerOpen中生成。
struct Pager {
...
int (*xGet)(Pager*,Pgno,DbPage**,int); // 获取页实际数据的函数。
sqlite3_file *fd; // 数据库文件fd
sqlite3_file *jfd; // 主日志fd
sqlite3_file *sjfd; // 副日志fd
PCache *pPCache; // cache总管
PagerSavepoint *aSavepoint; // 记录点
int nSavepoint; // 记录点数量
char *zFilename; // 数据库文件名
char *zJournal; // 日志文件名
int pageSize; //每页的字节数
}
常用流程#
打开数据库#
openDatabase
sqlite3_initialize
sqlite3PcacheInitialize
sqlite3PCacheSetDefault
把xFetch配置为pcache1Fetch
sqlite3BtreeOpen
sqlite3PagerOpen
打开指定的数据库文件.生成一个Pager实体,存到BtShared.pPager.
sqlite3PcacheOpen(pagerStress)
setGetterMethod
pPager->xGet = getPageNormal; // 配置xGet
sqlite3PagerReadFileheader
sqlite3OsRead
会通过os适配层最终对应到比如说unix的read
xGet通常配置为getPageNormal。具体实现了获取页数据。
大致是按页号查找对应的缓存,找到就直接返回。找不到时可能按LRU回收,可能新分配一个页cache,可能返回空。 具体看pcache1FetchNoMutex的注释,非常详细。
getPageNormal(Pager*,Pgno,DbPage**,int) // 读取页号为Pgno的页数据
sqlite3PcacheFetch // 先尝试从缓存里读
xFetch(pcache1Fetch)
pcache1FetchNoMutex
用hash找到筒,再遍历筒找页号是否存在.如果存在直接返回.否则走
pcache1FetchStage2
回收或新建cache
sqlite3PcacheFetchFinish
按他的设计cache有两层
底层中另有cache和page的抽象定义PCache1和PgHdr1,去承载原始的PCache和PgHdr.
逻辑是针对PCache1和PgHdr1来写.
流程结束后会转换一下,得到上层的PgHdr实体.
readDbPage // 如果是新的cache,那么从磁盘读数据并关联到这个cache。
sqlite3OsRead
读取页数据#
sqlite3PagerGet(Pager *pPager, Pgno pgno, DbPage **ppPage, int clrFlag)
用xGet读取指定页号的页数据到PgHdr // 广泛使用
写页数据#
sqlite3PagerWrite(DbPage*) // 把一个页标记为脏页、可写等。
pager_write
sqlite3PcacheMakeDirty
pcacheManageDirtyList(p, PCACHE_DIRTYLIST_ADD);
维护好链表
pagerAddPageToRollbackJournal
把页数据写入Pager的jfd.即把修改之前的页数据存入日志.
sqlite3PagerWrite只用来标记和存日志,一般会紧接着用put4byte、memcpy、memset之类函数处理实际数据。
b树开始一个事务#
sqlite3BtreeBeginTrans
sqlite3PagerBegin(Pager*, int exFlag, int)
pager开始一个事务
大体上是对pager的df也就是数据库文件争个锁
pagerLockDb
sqlite3OsLock
xLock
unixLock
unixFileLock
osSetPosixAdvisoryLock
osFcntl
fcntl // linux的fcntl
页同步#
sqlite3PagerSync(Pager *pPager, const char *zSuper)
sqlite3OsSync
xSync
unixSync
full_fsync
fsync
fsync在操作系统层面确认数据写到了硬件
提交#
看之前的opcode,最后一般是OP_HALT,就会进行收尾,用sqlite3PagerSync把数据固化到磁盘。
sqlite3VdbeHalt
vdbeCommit
sqlite3BtreeCommit
sqlite3BtreeCommitPhaseOne
sqlite3PagerCommitPhaseOne
sqlite3PcacheDirtyList // 获取所有脏页的cache。当即按页号排序。
syncJournal // 确保日志同步到了磁盘
sqlite3OsSync
pager_write_pagelist // 所有脏页写到磁盘
sqlite3OsWrite
xWrite
unixWrite
seekAndWrite
seekAndWriteFd
osWrite
write // 最终用linux的write写文件。
sqlite3PcacheCleanAll // 所有脏页标记为clean
sqlite3PagerSync // 页同步
sqlite3BtreeCommitPhaseTwo
sqlite3PagerCommitPhaseTwo
pager_end_transaction // 事务结束。做各种清理。
releaseAllSavepoints // 清掉所有记录点
按需把日志清掉.因为事务的数据更新实际已经完成.
页回滚#
从回滚日志一页一页地写回当前数据,实现回滚功能。
sqlite3BtreeRollback
sqlite3PagerRollback
pager_playback
readSuperJournal
loop
readJournalHdr
loop
pager_playback_one_page
sql的savepoint语句#
可rollback到某个记录点。或者commit到某个记录点。
sqlite3BtreeSavepoint
sqlite3PagerSavepoint
如果是commit
按需truncate日志文件
如果是rollback
pagerPlaybackSavepoint
loop
pager_playback_one_page