SQLite源码分析7 B树#
上次分析了sqlite的分页和缓存。这次分析B树流程。
需要先学会B树的基本算法。实际使用的可能是B+树或其他变种,这里统一说B树。
需要先学pager的实现。
需要参考sqlite的各种文件和数据格式(https://sqlite.org/fileformat2.html#record_format)。
数据结构#
shell状态#
struct ShellState { // 各种命令行相关数据
...
sqlite3 *db; // 数据库
}
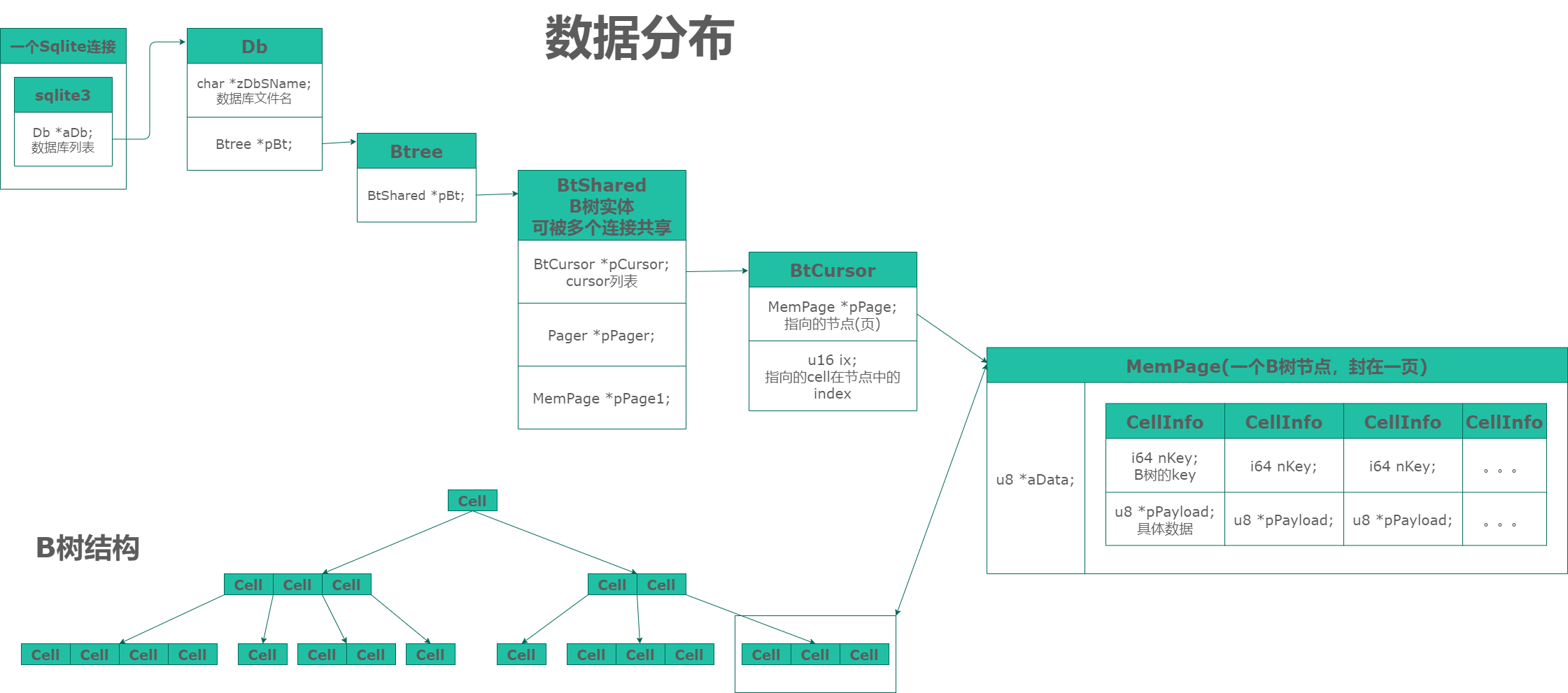
sqlite总管。每个数据库连接或者进程对应一个sqlite3实体。#
struct sqlite3 {
...
struct Vdbe *pVdbe; // 虚拟机列表
Db *aDb; // 每个数据库文件对应一个Db结构。aDb[0]是主数据库。1是临时。
int nDb; // Db的数量
}
struct Db {
...
char *zDbSName; // 数据库名字
Btree *pBt; // 该数据库对应的b树
Schema *pSchema;
};
每个数据库连接或者进程对应一个Btree实体。#
struct Btree {
...
sqlite3 *db; // 总连接信息
BtShared *pBt;
}
B树的一个节点。限定在一页。#
struct MemPage {
...
u8 intKey; // 是表b树还是index树
Pgno pgno; // 页号
u8 leaf; // 是否叶子节点
u16 nCell; // 包含几个cell
u8 *aData; // 页的实际磁盘数据。格式见见https://sqlite.org/fileformat2.html#record_format
BtShared *pBt; // 所属的B树
DbPage *pDbPage; // 对应的PgHdr,即page层的页实体信息。
}
BtCursor相当于一个指向b树某个具体节点的指针。#
struct BtCursor {
...
u8 eState; // 状态
Btree *pBtree; // 所属的b树
BtCursor *pNext; // cursor链表
CellInfo info; // 所指的cell的数据
Pgno pgnoRoot; // 根节点页号
MemPage *pPage; // 当前所指的页(节点)
MemPage *apPage[BTCURSOR_MAX_DEPTH-1]; // 存父节点关系,一级级往上直到根节点。BTCURSOR_MAX_DEPTH为20,b树最大深度,超过的话认为数据出现严重错误。
i8 iPage; // 当前指向页在apPage中的index。初始化为-1。在moveToChild时更新。
u16 ix; // 指向节点的的cell的index。
}
cell结构#
struct CellInfo {
...
i64 nKey; // key
u8 *pPayload; // 指向具体数据
u32 nPayload; // 数据大小
}
cell的具体数据#
struct BtreePayload {
...
const void *pKey; // index树的key数据。表b树用不着。
sqlite3_int64 nKey; // 表b树的主键。index树的pKey数据长度。
const void *pData; // 数据
int nData; // 数据长度
}
B树的操作#
把cursor挪到B树的根节点#
apPage存了父级关系,index-1就是往上走一级。
moveToRoot(BtCursor *pCur)
如果cursor的iPage>0
releasePageNotNull // 释放当前页
sqlite3PagerUnrefNotNull
sqlite3PcacheRelease
PgHdr的引用计数-1
PCache的引用计数-1
按情况pcacheManageDirtyList 加入脏链表
--iPage
不断对apPage的iPage做releasePageNotNull,直到iPage为0,即走到B树最顶端,即根节点.根节点不做释放.
如果pgnoRoot==0
即根是空的.返回空.
否则iPage<0,即cursor是新的,没有指向任何数据.
getAndInitPage
sqlite3PagerGet 用pager接口获取根节点页的实际数据,写入cursor的pPage.
把cursor挪到父节点#
moveToParent(BtCursor *pCur)
release当前节点,往上走一级.
cursor挪到页号为newPgno的子节点#
moveToChild(BtCursor *pCur, u32 newPgno)
更新apPage
getAndInitPage
挪到新页后ix总是设为0(即指向第一个cell)
cursor挪到最左#
moveToLeftmost(BtCursor *pCur)
获取cursor当前所指的cell信息,cell信息里存有下一层的页号.
不断做moveToChild直到达到叶子节点
cursor挪到最右#
moveToRightmost(BtCursor *pCur)
当前页aData中存了最右边的子节点的页号
不断做moveToChild直到达到叶子节点
查找#
以intKey这个key搜索对应的位置,把cursor挪到这个位置。
sqlite3BtreeMovetoUnpacked(BtCursor*, UnpackedRecord *pUnKey, i64 intKey, int bias, int *pRes)
检查cursor当前指向节点的key信息,如果已经是目标节点,直接返回.
moveToRoot 挪到根节点
for(;;)
二分比较当前的节点的cell的key,找到对应的位置.即得到了子节点的页号.
moveToChild进入下一层.
直到走到叶子节点.B+树需要走到叶子节点.
插入数据#
找到key所在节点,找到cell对应的位置,插入数据。
sqlite3BtreeInsert(BtCursor*, const BtreePayload *pPayload, int flags, int seekResult)
对于数据b树,即表b树.
如果cursor刚好指向要找的key
如果满足一定条件:刚好有可用空间
btreeOverwriteCell // 直接更新cell数据。即插入了数据。
返回
如果cursor的指向未准备好
sqlite3BtreeMovetoUnpacked // b树按key搜索。把cursor挪到对应的位置。
insertCell // 插入cell数据
如果节点中的cell数量超出b数规定,需要进行b树的balance操作.
删除cursor所指的数据#
sqlite3BtreeDelete
dropCell
按情况做balance
对B树做平衡#
插入或删除数据后可能会破坏b树规定的平衡,需要进行处理恢复平衡。
balance // 实现了三种方法供不同情况使用。之前学习B树时已实现过。这里不详细看代码了。
balance_quick
balance_deeper
balance_nonroot
分配新页#
当数据变多时就可能得分配新的页
allocateBtreePage
n = get4byte(&pPage1->aData[36]); // 获取空闲的页数,
如果n>0
复用空闲的页
如果n==0
pBt->nPage++; // b数的总页数+1。该值也作为新页的页号。
各种设置
定了页号,就知道了该页在数据库文件中的offset,就可以存取数据了。
具体例子#
初始化过程#
main()
ShellState data;
open_db(&data, 0); // 如果文件不存在,会推迟到数据第一个命令后执行。
openDatabase
db = sqlite3MallocZero( sizeof(sqlite3) ); // 分配sqlite3的内存
sqlite3BtreeOpen
sqlite3MallocZero(sizeof(Btree))
sqlite3PagerOpen // 初始化Pager
sqlite3PagerReadFileheader
直接读数据库文件头(100字节)
// 各种初始化,写入db。
db写入ShellState
循环处理命令
数据库的数据是怎么加载到b树的?加载顺序?加载数量?又是怎么存的?#
看一个例子,插入一条记录(5)。结合生成的opcode分析一下。
sqlite> EXPLAIN insert into xcc values(5);
addr opcode p1 p2 p3 p4 p5 comment
---- ------------- ---- ---- ---- ------------- -- -------------
0 Init 0 17 0 00 Start at 17
1 OpenWrite 0 3 0 1 00 root=3 iDb=0; xcc
2 OpenWrite 1 4 0 k(1,) 00 root=4 iDb=0; sqlite_autoindex_xcc_1
3 Integer 5 2 0 00 r[2]=5
4 NewRowid 0 1 0 00 r[1]=rowid
5 HaltIfNull 1299 2 2 xcc.id 01 if r[2]=null halt
6 Affinity 2 1 0 D 00 affinity(r[2])
7 Noop 0 0 0 00 uniqueness check for sqlite_autoindex_xcc_1
8 SCopy 2 4 0 00 r[4]=r[2]; id
9 IntCopy 1 5 0 00 r[5]=r[1]; rowid
10 MakeRecord 4 2 3 00 r[3]=mkrec(r[4..5]); for sqlite_autoindex_xcc_1
11 NoConflict 1 13 4 1 00 key=r[4]
12 Halt 1555 2 0 xcc.id 02
13 MakeRecord 2 1 6 00 r[6]=mkrec(r[2])
14 IdxInsert 1 3 4 1 10 key=r[3]
15 Insert 0 6 1 xcc 39 intkey=r[1] data=r[6]
16 Halt 0 0 0 00
17 Transaction 0 1 3 0 01 usesStmtJournal=0
18 Goto 0 1 0 00
b树只加载key。那么如果有大量key比如有1亿条数据即1亿个key呢?
从初始情况开始,sqlite3BtreeOpen只是初始化pager和b树,并没有读任何数据页。1 OpenWrite 0 3 0 1
在表b树打开cursor。cursor的pgnoRoot定为p2也就是3。
allocateCursor
sqlite3BtreeCursor
btreeCursor
到此完成cursor的初始化。iPage为-1。pgnoRoot为3。
4 NewRowid 0 1 0
生成新id。
查找B树里最后一个数据。
这时b树是空的,但如果磁盘上有1亿条数据,就必须找到第1亿条数据的key。
sqlite3BtreeLast
moveToRoot // 移到最上
getAndInitPage
// 读pgnoRoot页磁盘数据
// 包括根节点的各种信息,cell列表,子节点页号等等。
// 见https://sqlite.org/fileformat2.html#record_format
moveToRightmost // 移到最右边即最后一个数据
while(不是叶子节点)
pgno = get4byte(&pPage->aData[pPage->hdrOffset+8]); // 按规定获取最右边的子节点页号
moveToChild // 往下走
// 如果不存在最后一个数据,说明表是空的,id从1开始,返回1。
// 如果最后一个id<MAX_ROWID,返回id+1。
// 否则生成一个随机的id,如果id不存在,就用这个id。尝试100次。
从这里可以看出,找一个key的位置不需要加载所有的节点,只加载路径上的结点。 而sqlite限定了b树最大20层,而且每次cursor往上走时会释放之前的页,所以不会有非常大的消耗。
13 MakeRecord 2 1 6 00 r[6]=mkrec(r[2])
按规定组装数据,不详细看了。见 https://sqlite.org/fileformat2.html#record_format15 Insert 0 6 1 xcc 39 intkey=r[1] data=r[6]
用上述的sqlite3BtreeInsert插入数据16 Halt 0 0 0
很快进入pager的commit流程。pager会处理好写磁盘和回滚等细节,不需要b树层关心。
sqlite3VdbeHalt
vdbeCommit
sqlite3BtreeCommitPhaseOne
sqlite3PagerCommitPhaseOne
sqlite3BtreeCommitPhaseTwo
sqlite3PagerCommitPhaseTwo